@ 상황 설명 : gpt4o를 이용해서 다수의 문서를 인용해야만 답변이 가능한 RAG용 질문 데이터셋을 생성해보자.

@ 순서
<RAG 학습용 질문 데이터 생성 및 정제>
<gpt4o에게 검색된 문서로부터 질문의 답변을 작성하게 하기>
<최종 생성된 RAG 질문-답변 학습용 데이터셋>
허깅페이스에 데이터 업로드할 차례...
@ 활용 데이터 : 허깅페이스 "runiarang/klue-mrc-bge-m3" 데이터 중 500개 샘플링
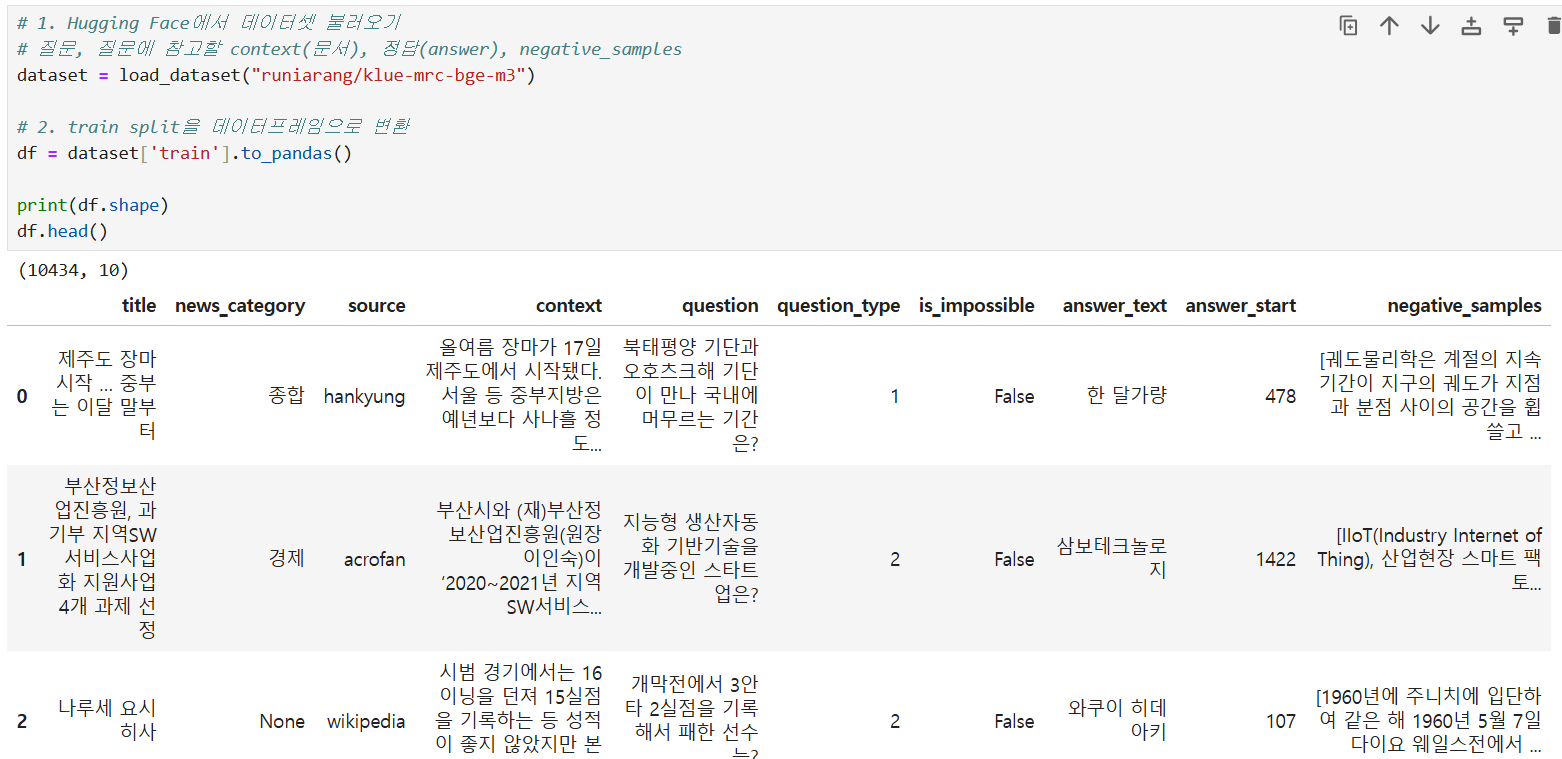
# title : 기사(문서) 제목
# news_category : 뉴스 카테고리
# source : 출처(언론사/출판사/위키 등)
# context : 참고 문서 - 모델이 정답을 추출할 수 있는 텍스트가 포함됨
# question : 질문(해당 본문(context)에 대해 묻는 질문)
# question_type :
# is_impossible : 질문에 대해 본문에서 정답을 찾을 수 있는지 여부(False: 정답이 존재, True: 정답이 본문에 없음)
# answer_text : 답변
# answer_start : 정답(answer_text)이 context 내에서 시작되는 문자 인덱스 위치
# negative_samples : 정답이 아닌 오답 후보 문장(모델 학습 시 distractor(혼동 유발 요소)로 활용 가능)
@ gpt4o로 다수의 문서를 인용해야 답변 가능한 질문 생성
# 시스템 프롬프트 : "당신은 주어진 문서로부터 2~3개 이상의 문서를 인용해야만 답변이 가능한 질문 5개를 제안해야 합니다...."



-> 답변을 보니까 ref1, ref3 두 개의 문서를 이용해서 답변하고 있다.
-> gpt4o가 만든 질문이 다수의 문서를 인용해서 답변하도록 잘 만들어진 것을 확인할 수 있다.
@ gpt4o가 다수의 문서를 인용해야만 답변 가능한 질문을 만들었지만, 이것이 잘못 만든 질문인 경우 => False
-> False 질문들은 제거해야 한다.


# -> 다수의 문서를 인용해야 답변 가능한 질문을 데이터당 1개씩, 총 500개 생성해내었다.
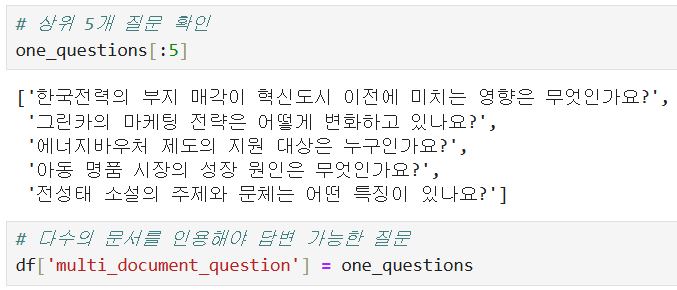
@ 최종적으로 만들어진 RAG 질문-답변 학습용 데이터셋

# multi_document_question : 다수의 문서를 인용해야만 답변 가능한 질문
# multi_document_answer : 답변
# search_result : 검색한 문서
# extracted_ref_numbers : 인용한 문서 번호
@ 허깅페이스에 데이터셋 업로드 : "klue-mrc-multi-document-answer"

@ 만들어진 데이터셋 불러오기
'LLM 파인튜닝' 카테고리의 다른 글
| [한국어 데이터셋] 허깅페이스 주요 한국어 파인튜닝 데이터셋 종류 (0) | 2025.08.26 |
|---|---|
| [ai100-5T] [RAG 파인 튜닝] klue mrc 데이터 파인튜닝 후 RAG QA 테스트 (2) | 2025.08.25 |
| [ai100-4T] [RAG 학습 데이터 생성2] no aswer 질문 데이터 만들기 (0) | 2025.08.25 |
| [ai100-2T] [경제 뉴스 예측 파인튜닝 모델 만들기2] 허깅페이스 trl로 경제 뉴스 llama3 파인튜닝 (3) | 2025.08.15 |
| [ai100-1T] [경제 뉴스 예측 파인튜닝 모델 만들기1] 라마팩토리로 경제 뉴스 llama3 파인튜닝 (2) | 2025.08.13 |